Speed up SvelteKit Pages With a Redis Cache
Faster pages and fewer database hits
Contents
- Introduction
- Why you might use SSR instead of SSG
- SvelteKit Output Cache Implementation
- Performance Result
Introduction
SvelteKit provides a range of rendering options - from Static Site Generation (SSG), through Server-Side Rendering (SSR) to Client-Side Rendering (CSR) and the ability to transition between them (e.g. SSR the initial request and then switch to CSR).
Obviously, SSG is the fastest at runtime and the least expensive to host - everything has been rendered in advance and you just need to serve out the static content. If you have a limited number of pages, no dynamic server content and only update the site occasionally it can be a great option which is why it has a sweet-spot with blogs.
Why you might use SSR instead of SSG
If you have a dynamic site (e.g. you want to edit your blog from any device, without having github and the SSG generator installed) or your site is simply too large so that updates are impractical (e.g. an e-commerce site with millions of products) it may be less suitable.
However, you can get an almost SSG-like site performance experience by using SSR with output caching. In this scenario you still have to have a system that fetches data from a data-store and renders pages on the server, but you can avoid the work of re-rendering them again by saving the output in a cache and serving it to future requests for the same content.
It’s very close to SSG in terms of performance and can save hits on your database.
SvelteKit Output Cache Implementation
The first thing you’ll need is a cache. If you have limited content you might be able to get away with using an in-memory LRU cache but if you are using any kind of serverless hosting this doesn’t allow the cached data to be re-used and invalidating the cached entries becomes difficult or impossible without more work.
Redis as the Cache
I’m using Redis because it’s blazingly fast and also provides additional useful features that take it way beyond purely cache-only services such as Memcached, but use whatever works for you.
Redis provide a free small cloud instance but most cloud hosting platforms provide it as a service and hosting your own cloud instance is also an option.
Once you have an instance running, you need a client to connect to it and talk it’s language. I’m using the official node-redis package. This is about the simplest client possible:
import { env } from '$env/dynamic/private';
import { createClient } from 'redis'
export const redis = createClient({ url: env.REDIS_URL })
await redis.connect()This makes use of the $env/dynamic/private import which allows the REDIS_URL to be defined using a .env file during development and as an environment variable in production, 12-factor config style, rather than potentially exposing production credentials in the built code or source repository.
Use hooks.server for output caching
We’ll make use of this Redis client in a server-side hook. This is a feature of SvelteKit that allows you to intercept every request and control how it is handled.
The actual “SvelteKit” page rendering execution part happens when you call resolve(event) (both the function and event parameter are passed in to the hook). But we don’t need to call it. If we can get the content that the rendering would have produced from someplace else, we can then return it directly. That means we avoid any database fetches that happen and the work that SvelteKit has to do to assemble the data and templates into HTML output. However fast the framework executes, it’s nearly always faster not to do that work.
import { redis } from './redis'
import type { Handle } from "@sveltejs/kit"
export const handle: Handle = async ({ event, resolve }) => {
const { url } = event
// Create a unique key to store the page in the
// cache. I'm using "rendered" to differentiate
// entries from other data in Redis and the "v1"
// will allow invalidating the entire cache if
// the application code will change rendering.
// For a blog, I don't want to alter the cache
// on every querystring parameter otherwise it
// reduces the cache hit-rate due to parameters
// other sites may add (such as "fbclid").
const key = `rendered:v1:${url.pathname}`
// ideally this is the only network request that
// we make ... it will return an empty object if
// the page wasn't cached or a populated object
// containing body and headers
let cached = await redis.hGetAll(key)
if (!cached.body) {
// if it wasn't cached, we render the pages
const response = await resolve(event)
// then convert it into a cachable object
cached = Object.fromEntries(response.headers.entries())
cached.body = await response.text()
if (response.status === 200) {
// and write it to the Redis cache ...
// NOTE: although this returns a promise
// we don't await it, so we don't delay
// returning the response to the client
// (the cache write is "fire and forget")
redis.hSet(key, cached)
}
}
// we end up here with the same object whether
// it came from the cache or was rendered fresh
// and we just return it as the response
const { body, ...headers } = cached
return new Response(body, { headers: new Headers(headers) })
}Performance Result
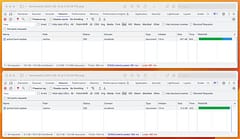
The first request to the page will operate as normal. In the case of this blog engine that means going to Firestore to request the markdown content for the page, looking up related pages using the “vector similarity” feature of Redis and then fetching those pages from Firestore (long term, everything will probably end up in Redis alone). But once rendered, until the blog is invalidated by publishing new content, subsequent requests can be satisfied from the cache. On the server, these are typically handled in single-ms times vs several hundred ms for uncached that fetch Firestore data and convert and render markdown. The ~70ms TTFB time is about as fast as any request round-trip I see to my location from Google (where this is hosted).
Because we also stored the HTTP headers in the cache SvelteKit is still able to negotiate a conditional response and only return a 304 Not Modified if the client has already downloaded the content before. So the TTFB is around the same but we don’t need to actually download it, providing a quicker overall response:
So always-fresh content, with reduced database hits and faster responses.